
周二,OpenAI发布了最新的文生图模型。该公司称,已“把目前最先进的图像生成器整合到GPT-4o模型里”,这让图像生成“不仅画面精美,而且颇具实用价值”。
此前版本的ChatGPT虽具备图像生成能力,但在融合多种广泛概念以可靠地创建图像方面,存在不足。
OpenAI首席执行官Sam Altman将此次发布形容为“创作自由度达到了新高度”。
有哪些新升级?
OpenAI在新闻稿中介绍,GPT-4o的图像生成功能十分强大。它能准确渲染文本,精确依照提示操作,还能利用4o自身的知识库以及聊天上下文。
这让用户能更轻松地生成符合设想的图像,通过视觉效果更高效地沟通。
具体体现在以下几个方面:
文本融入更出色:GPT-4o如今能够在生成的图像中添加文字,并且确保文字清晰易读、位置恰当,进一步丰富图像内涵。


上下文理解能力增强:基于上下文信息,GPT-4o可以生成连贯一致的图像。举例来说,当用户设计视频游戏角色时,在后续的优化与尝试过程中,该角色的外观能在多次生成中保持一致。


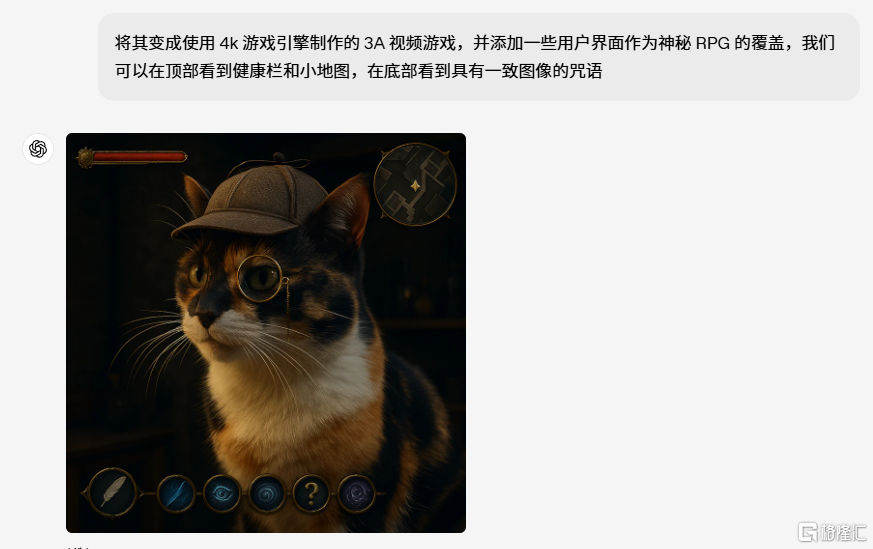
可绘制物品数量更多:GPT-4o能响应更详细的提示,十分注重细节。其他竞争对手的AI图像生成器在绘制大约5-8个物体时就会遇到困难,而GPT-4o可以精准绘制用户指定的多达20种不同物品。


情境学习更智能:GPT-4o能以上传的图像作为参考,生成与之相似的图像。
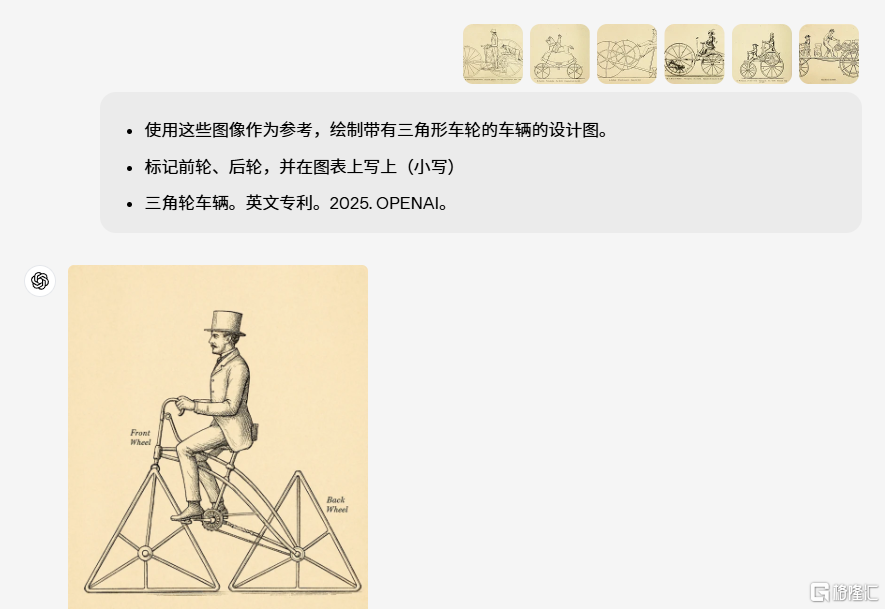
知识运用更直观:GPT-4o能够将知识在文本和图像间建立联系,从而构建出一个更智能、高效的知识模型。

照片风格更丰富:通过对多种图像风格的图像进行学习训练,GPT-4o既能生成,也能将图像转换为多种风格,从手绘草图到高分辨率的照片写实风格都不在话下。

此外,GPT-4o的图像生成在商业应用领域也展现出巨大潜力。在品牌设计方面,它能生成带有精准文本的徽标、海报以及广告;教育领域,可创建科学图表、信息图以及历史图像用于教学;游戏开发中,能保证角色在不同设计迭代中保持形象一致。
“文本生成领域的巨大飞跃”
OpenAI宣布,从周二起,新版ChatGPT将面向ChatGPT Plus、Pro、Team以及免费版用户开放使用。该公司还透露,该功能也将很快向Enterprise、Edu用户开放,并通过应用程序编程接口(API)提供服务。
回顾来看,2022年底,初代ChatGPT惊艳亮相,它凭借对海量互联网文本的深度分析,能够回答问题、创作诗歌以及生成计算机代码,但无法生成图像。
大约一年后,OpenAI才推出了可以生成图像的新版ChatGPT,即DALL-E,不过那时ChatGPT和DALL-E是相互独立的系统。
此次更新意味着,OpenAI把图像生成工具从DALL-E更换为GPT-4o。
OpenAI研究员GabrielGoh表示:“这是一项全新的技术。我们不再将图像生成和文本生成分开处理,而是希望把它们融合在一起。”不仅如此,该模型还被集成到OpenAI的视频生成平台Sora中,进一步拓展了多模式功能。
独立人工智能顾问AllieK.Miller在X平台上发文称,这是“文本生成领域的巨大飞跃”,也是她所见过的“最出色的”人工智能图像生成模型。
不过,尽管GPT-4o取得了显著进步,但仍然面临一些挑战。
比如存在裁剪问题,大型图像有时可能会被裁剪得过紧;在非拉丁文字的文本准确性方面,某些非英语字符可能无法正确显示;对于小文本中的细节保留不足,高度详细或小字体的文本可能会失去清晰度;编辑精度也有待提升,修改图像的特定部分可能会意外影响到其他元素。
OpenAI正在积极采取措施,通过持续优化模型来解决这些问题。
主题测试文章,只做测试使用。发布者:北方经济网,转转请注明出处:https://www.hujinzicha.net/10748.html