
在本系列报告的第一篇中,我们深度讨论了DeepSeek(以下简称DS)技术创新对训练硬件的需求变化。除了训练以外,DS团队在最新一系列的开源成果发布中针对推理任务也做出了双重维度的创新:一方面通过模型优化降低硬件资源占用,另一方面通过硬件工程化优化以发挥硬件最大效能。
摘要
模型创新:借助MLA、NSA等技术优化加速推理。在上一篇聚焦训练任务的报告中,我们重点解读了DS大语言模型中前馈网络(FFN)架构部分由稠密演化到稀疏(MoE,专家模型)产生的影响,同时,DS在注意力机制(Attention)部分也做出了创新。针对传统Attention部分需要计算所有词对之间关联的特性,在处理文本变成长时,计算量和内存消耗会呈现大幅增长。我们认为DeepSeek独创的多重潜在注意力机制(Multi-Latent-Attention,MLA)方法,通过将占用内存较大的KV矩阵投射到隐空间来解决KV cache占用过多的问题,类似“高度概括的全局视角”;而近期,DS团队又在最新发布的论文[1]中指出,可采用原生稀疏注意力(Native Sparse Attention, NSA)方法,从底层设计避免计算无关词对注意力,类似“关键信息的详细洞察”,直接对序列长度进行压缩,优化推理算力、存储开销。
硬件工程优化:DS团队采用PD分离+高专家并行度策略充分释放硬件性能。首先,针对推理过程中预填充(Prefill)和解码(Decode)两个对计算/存储资源要求的差异性较大的任务分别做了针对性的硬件优化配置;其次,为实现更好的计算单元利用效率并平衡通信开销,DS团队在Decode阶段采用了高达320的专家并行度(Expert Parallel)来布置推理硬件。DS团队也开源了MLA相关内核(Kernel),直接解密MLA结构在NV硬件上的具体实现,我们认为这给开发者优化适配其他硬件(如国产卡)提供了思路。
硬件需求启示:1)集群推理成为主流形式,利好以太网通信设备需求;2)DS团队为市场带来高水平的开源模型后,云端/私域部署需求快速增长,我们测算仅微信接入DS模型有望带来数十万主流推理卡的采购需求。结构上,除海外产品外,国产算力链以其快速的适配也迎来了商业机会。
风险
生成式AI模型创新、AI算力硬件技术迭代、AI应用落地进展不及预期。
DeepSeek在模型推理过程中引入了哪些创新?
模型创新
V3/R1延续V2的MLA架构,优化KV Cache,加快推理速度
传统的Transformer模型通常采用多头注意力机制(Multi-Head-Attention, MHA),但在生成过程中,随着前置序列的长度变长,需要读取的KV cache也将越来越大,数据的传输成本增加,KV缓存会限制推理效率。减少KV缓存的策略包括MQA和GQA等,它们所需的KV缓存规模较小,但性能却无法与MHA相比。
图表1:MHA、GQA、MQA、MLA 架构对比


资料来源:DeepSeek V2 技术报告,中金公司研究部
DeepSeek 团队创新引入了多头潜在注意力机制(Mult-Head-Latent-Attention,MLA)技术,通过压缩 KV 存储,即不对所有的 Key 和 Value 进行存储,而是存储一个低秩的变量C,将其投影至隐空间,在计算过程中再恢复出 Key 和 Value,得出原始值,大幅降低存储需求。按照此方式,KV Cache 只存储所有注意力头中 KV 共性的内容,差异性内容在推理时进行计算,将解码过程的访存密集型任务转换为计算密集型任务。在具体实现机制上,由于推理过程中将隐空间向量恢复到KV原空间所需的矩阵可以与其他矩阵进行吸收合并,因此并未增加计算量,巧妙地获得了“省存储但并无多余计算开销”的效果。
图表2:DeepSeek MLA实现方法示意图
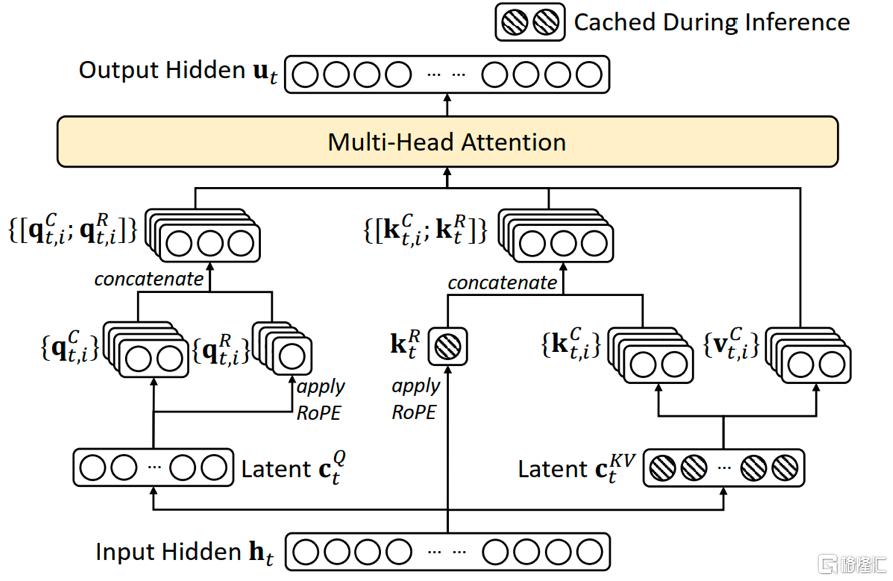
资料来源:DeepSeek V2 技术报告,中金公司研究部
根据DeepSeek发布的《DeepSeek-V2技术报告》,MLA在KV缓存中存储的元素数量较少,相当于只有2.25组的GQA,但可以实现比MHA更强的性能。如下图所示,两个MoE模型(分别具有16B和250B总参数)使用不同的注意力机制时,MLA在大多数基准上都优于MHA。MLA 在减少 KV 缓存的基础上,还提高了性能与效率。
图表3:MoE模型使用不同注意力机制的表现
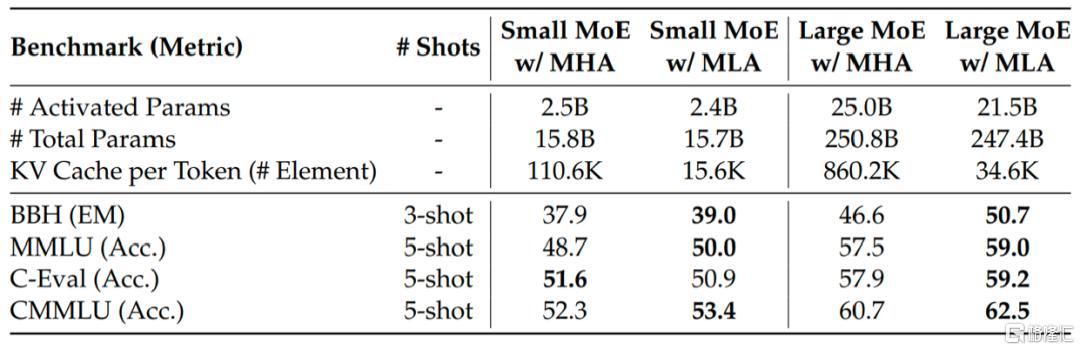
资料来源:DeepSeek V2技术报告,中金公司研究部
NSA技术直接压缩序列长度,实现高效的长文本建模
近期,DeepSeek团队又提出的新的原生稀疏注意力机制(Native-Sparse-Attention,NSA)[2],集成了分层字符建模,将算法创新与和硬件对齐的优化相结合,以实现高效的长文本建模。NSA 通过将键和值组织成时间块并通过三条注意力路径处理它们来减少每个查询的计算:Token压缩、Token选择、滑动窗口。1)Token 压缩:聚合块内信息生成压缩的粗粒度表示,保留全局语义;2)Token选择:基于压缩块的注意力得分,只保留前 N 的块参与计算;3)滑动窗口:在局部范围内保持一个连续的上下文窗口,从而确保模型不会错过局部关联的重要信息。
图表4:DeepSeek NSA架构示意图
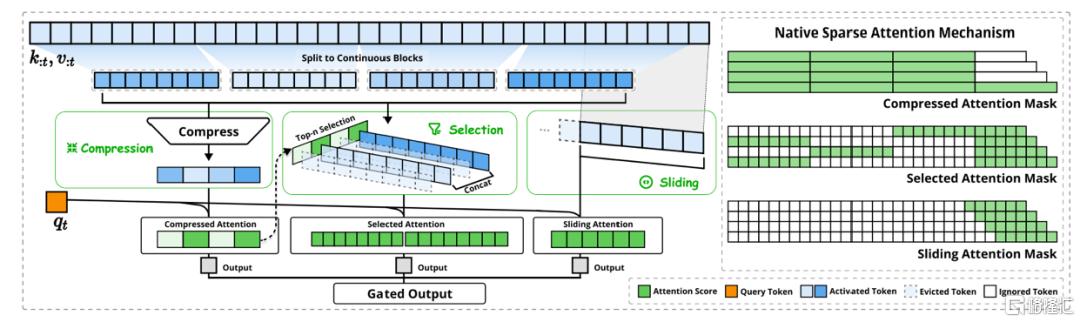
资料来源:DeepSeek NSA技术论文,中金公司研究部
在此基础上,NSA 给出了一套软硬协同的解决方案,通过定制化 GPU 内核(Kernel,即在GPU上并行执行的一段代码),充分挖掘硬件潜力,将理论上的计算量减少转化为实际的性能提升。DeepSeek NSA内核的专有特性主要为: 1)以组为中心的数据加载:一次性加载一个组内所有头的 query,以及它们共享的稀疏KV块;2)共享 KV 获取:同组的共享 KV只需要加载一次到GPU高速缓存,减少内存访问次数;3)网格上的外部循环:用NVIDIA Triton网格调度器更好地调度任务,GPU 可以更高效地并行处理任务。
图表5:DeepSeek NSA 定制 GPU 内核设计示意图
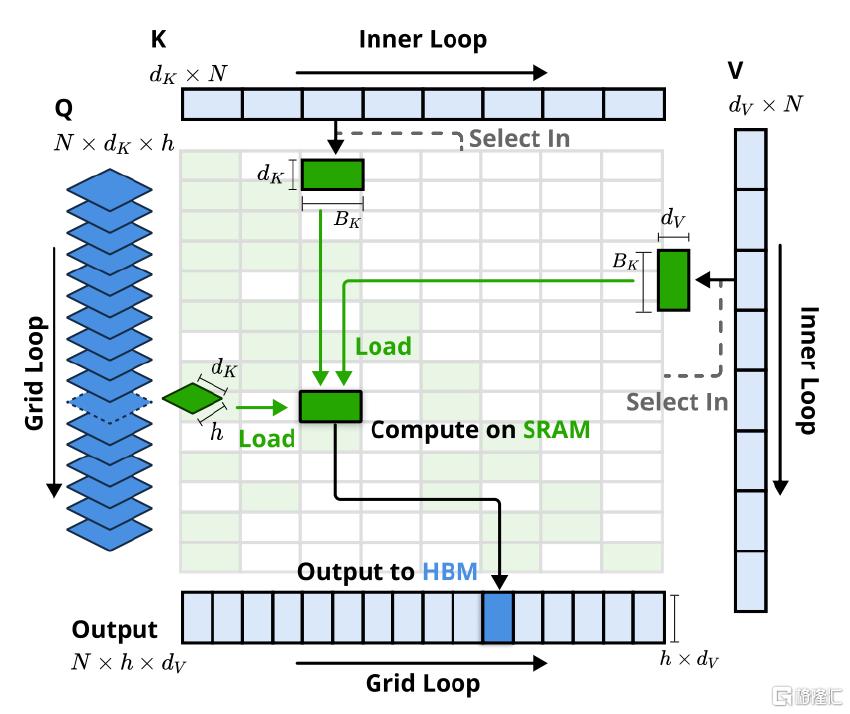
资料来源:DeepSeek NSA技术论文,中金公司研究部
在实证结果上,NSA 虽然为稀疏架构,但仍然在一般通用性能上有着卓越的表现,在场上下文的表现上尤为出色。在效率上大大提升了解码速度(与 KV 缓存量密切相关,如下图6所示),随着解码长度的增加,NSA 低延迟特性体现地愈发明显,在 64k 上下文长度下实现了高达 11.6 倍的加速。同时,DeepSeek发布的NSA论文也指出,此技术同样对训练过程有加速作用,在 64k 上下文长度下实现了 9.0 倍的前向加速和 6.0 倍的反向加速。
图表6:NSA 与全注意力机制在不同文本长度下内存访问效率对比
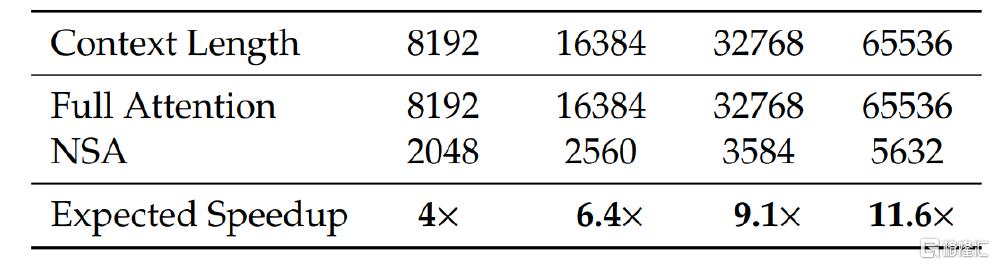
资料来源:DeepSeek NSA 技术论文,中金公司研究部
我们认为,对比之前在 V2、V3 中应用的 MLA 机制,MLA是压缩KV Cache的内存占用,而NSA是从序列长度的压缩;NSA 架构更关注局部关键细节而 MLA 架构更关注全局视角建模,两者各有所长,除推理应用外,我们认为DeepSeek 也有望在后续训练中整合两者来提高模型整体能力。
图表7:全面认识DeepSeek注意力机制层面的创新:各类机制对比

资料来源:DeepSeek-V2技术报告,DeepSeeek NSA技术论文,中金公司研究部
硬件工程化创新
Prefill/Decode分离,平衡访问内存与计算
我们看到,在推理端DeepSeek采用了Prefill(预填充)/Decode(解码)分离的策略(简称PD分离策略)。PD分离通过将数据预填充和解码过程拆分到不同的计算设备上各自独立运行,来提升推理效率和准确性。Prefill阶段主要负责将输入数据预处理并加载到硬件中,从计算特性上来说属于计算密集型,完成KV Cache的生成后,prefill阶段本身无需继续保留这些缓存;而Decode阶段则是根据模型的计算结果生成输出,从计算特性上来说属于储存密集型,通常涉及大量、频繁地访问KV Cache;二者的计算特性不同导致难以在单一设备上运行时同时提高两个阶段的能力,如下图所示。我们认为将 Prefill 与 Decode 过程分离,并选择适配的硬件是未来 MoE结构模型硬件工程优化的趋势。
图表8:Prefill Decode 阶段输出随 Batch size 变化
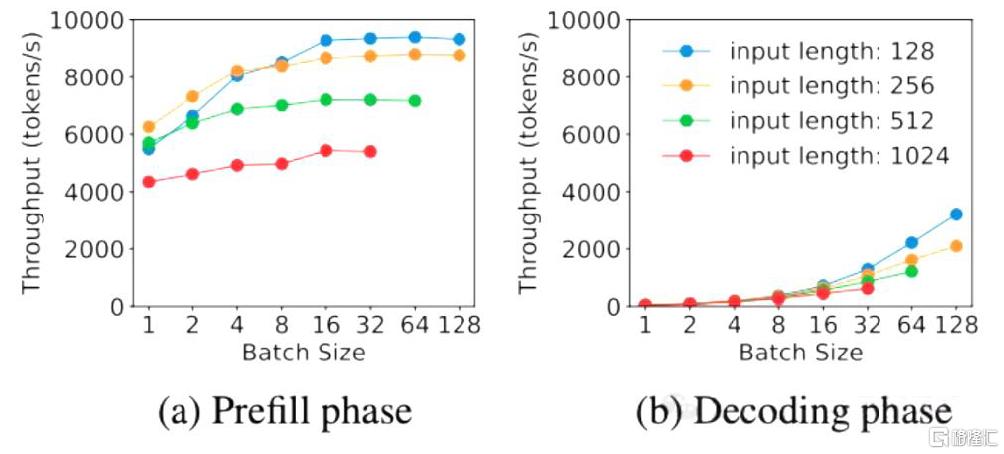
资料来源:DistServe 技术论文[3],中金公司研究部
在《AI进化论(1)》中,我们已经对各种并行计算策略做了基础分析,再此不再赘述。针对Prefill和decode阶段不同的需求,在硬件工程化具体的实施上DeepSeek也采取了针对性的策略,以DeepSeek-V3模型为例:
► Prefill过程采取4节点32GPU的配置,其中Attention部分采取TP4(Tensor Parallel)+SP(Serial Parallel)+DP8(Data Parallel)的配置,MoE部分采取EP32(Expert Parallel)的配置,以保证每个专家都有较大的batch size,增加计算效率,All2All通信方面域训练设置相同,不拆分张量。
► Decode阶段采取40节点320GPU的配置,其中Attention部分采取TP4+SP+DP80的配置,MoE部分采取EP320的配置。
特别来看,在Prefill和Decode过程中,DS团队还分别设置了“冗余专家(Redundant Expert)”、以及动态冗余策略来优化硬件使用。具体来看,冗余专家是指系统会检测高负载的专家,并将这些专家冗余部署在不同的 GPU 上,从而平衡每个 GPU 的负载;而动态冗余策略是指,即在每个推理步骤中动态选择激活的专家,以进一步优化推理效率,即若在推理过程中,某个专家因为处理了过多的 token 而负载过高,DeepSeek会自动将该专家的部分负载转移到其他 GPU 上的冗余专家,从而确保推理过程的顺利进行。最终的部署方案是,DeepSeek-V3模型在Prefill过程中单GPU承载9个专家,Decode阶段单GPU承载1个专家,320卡中256个GPU承载原模型中的专家,64个GPU负责冗余/共享专家。同时,为减少通信开销,微批次(Micro-Batch)的使用也很普遍。
图表9:张量并行(Tensor Parallel,TP)硬件部署示意图
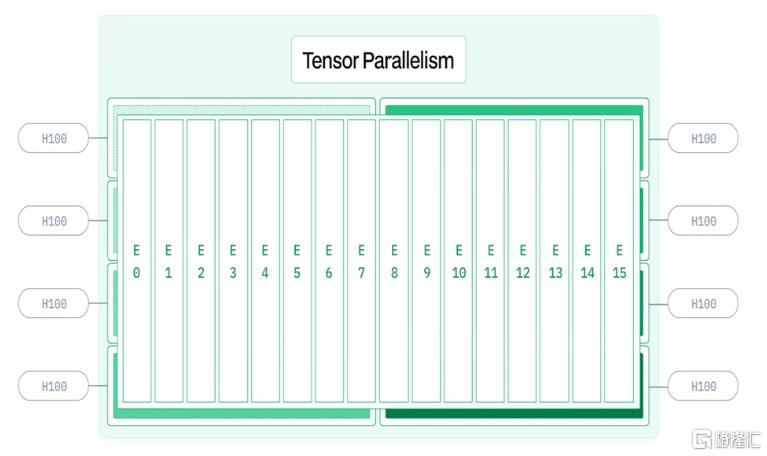
资料来源:https://www.baseten.co/blog/how-multi-node-inference-works-llms-deepseek-r1/,中金公司研究部
图表10:专家并行(Expert Parallel,EP)硬件部署示意图
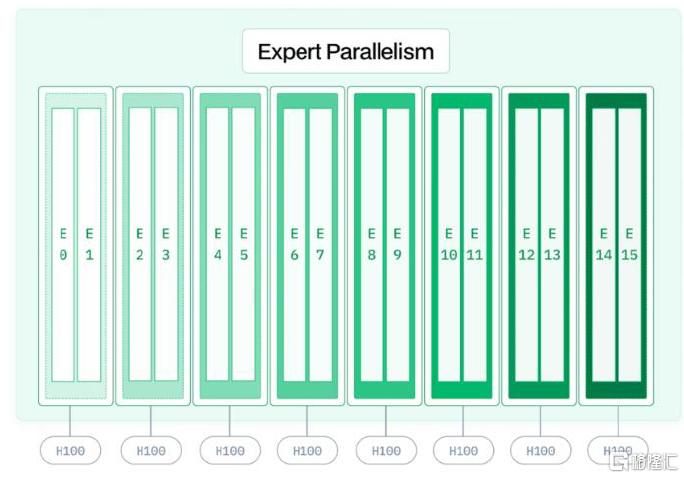 资料来源:https://www.baseten.co/blog/how-multi-node-inference-works-llms-deepseek-r1/,中金公司研究部
资料来源:https://www.baseten.co/blog/how-multi-node-inference-works-llms-deepseek-r1/,中金公司研究部
增加专家并行度以应对MoE结构变化,对网络性能提出挑战
我们看到,随生成式人工智能技术发展,由于Scaling Law的存在,MoE为提升性能和泛化能力开始面临参数量较大的问题。以 DeepSeek-V3为例,在仅考虑把专家模型激活部分加载至显存部分来看,序列长度2048、FP8精度推理情况下,25用户并发所占用显存已接近NVIDIA H系列芯片显存上限,实际应用场景必然会涉及动态路由的不可预测性、以及高并发需求,可能涉及多卡推理,甚至多节点推理情况;若考虑将671B模型参数全部加载至显存中,仅模型权重部分单节点都能力容纳,分布式推理需求应运而生。实际上,为了实际的推理性能,DeepSeek-V3/R1这类混合 MoE 稀疏架构模型甚至采用了内存兜底策略外更高的并行度。在上文中我们已经提及,为获得最大化吞吐量,以及考虑到全局均衡、通信瓶颈高等因素,Prefill阶段采用了32的专家并行度(EP32),而对于Decode阶段,是一个通信瓶颈较低(每次只生成一个token)的场景,为实现最小化单步延迟,采用了高达320的专家并行度(EP320),Decode硬件资源部署在40个节点上,这对网络性能提出了一定挑战。
图表11:推理显存需求计算
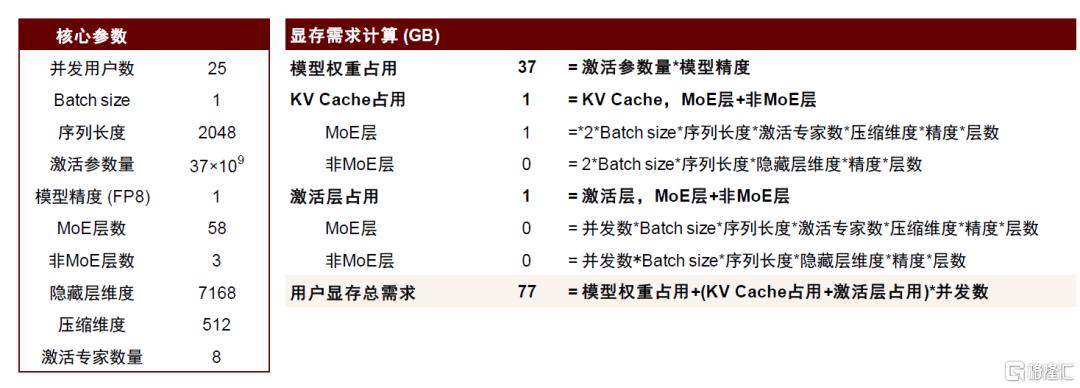
资料来源:DeepSeek-V3技术报告,中金公司研究部
图表12:不同应用阶段专家并行度对比

资料来源:DeepSeek-V3技术报告,中金公司研究部
启示:推理硬件技术发展趋势和市场需求的变化方向?
推理系统部署方式:由单卡向集群演变,关注以太网投资机会
推理系统部署走向分布式集群。无论是出于均衡算力和存储的目的,还是出于提升专家模型性能的目的,单卡或单台服务器都已难支持MoE架构下的推理任务。以671B参数的“满血版”DSV3模型来看,甚至需要几十台H800服务器才能实现高效推理。我们认为,随着推理集群规模的增长,模型推理性能呈现上升趋势,规模效应正逐步显现,分布式部署有望成为未来范式。
Scale-up超节点有望进一步释放GPU性能。我们认为,推理任务高吞吐、低时延的特性,使得scale-up网络在推理需求释放的AI时代中有望发挥重要作用。以英伟达NVL72为例,其内部包含72块Blackwell GPU和36个Grace CPU,在GPT-MoE-1.8T大模型的推理任务上可实现每卡116 tokens/s的输出吞吐量,是HGX 100系统的近30倍。中国信通院[4]与产业力量发起ETH-X计划,认为超节点推理时每GPU吞吐量提升30%。
图表13:英伟达GB200 NVL72与HGX H100单卡推理速度对比(GPT-MoE-1.8T)
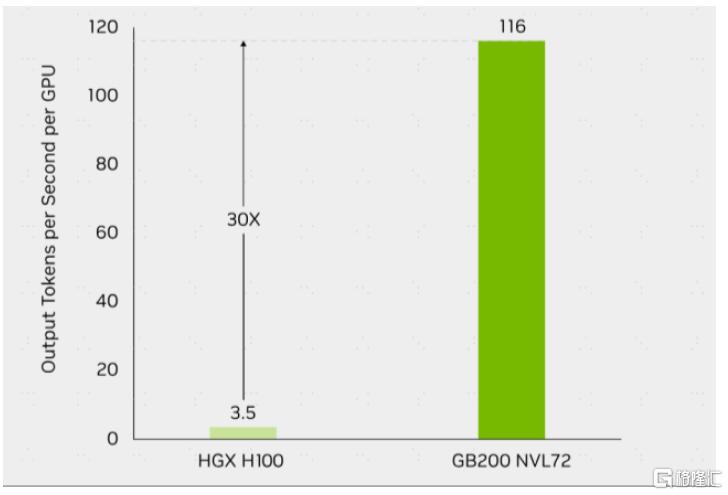
资料来源:NVIDIA官网,中金公司研究部
注:1):ETH-64的基本参数:64 GPUs,70B+16MoE,Seq=64k/1k,FTX<5s,TTL<50ms
图表14:ETH-64系统单GPU吞吐量较8卡服务器提升30%
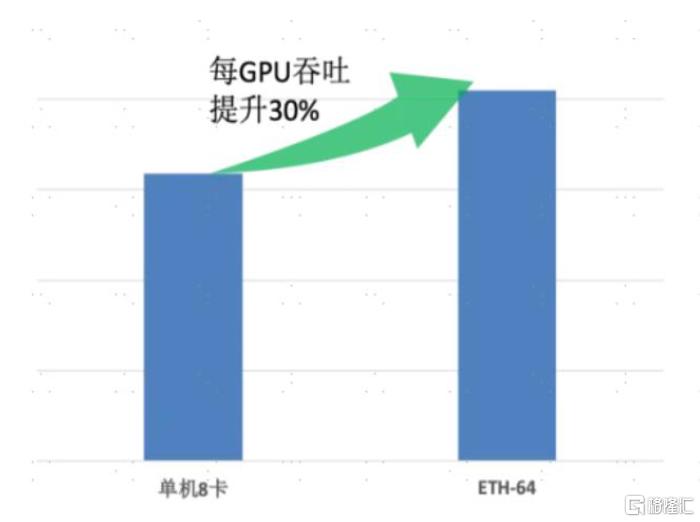 资料来源:中国信通院,中金公司研究部
资料来源:中国信通院,中金公司研究部
以太网在Scale-up网络中开启渗透。在带宽方面,以太网基本保持每两年带宽翻一番的迭代速度,51.2Tbps产品已实现商用,我们预计2025年102.4Tbps的产品亦有望推出,相较PCIe 5.0交换芯片4.6Tbps的交换容量处于领先。时延方面,业内一些51.2Tbps的转发延迟已低于400ns,且通过优化可进一步降至200ns以下,属于行业领先水平。从技术的角度看,以太网已具有取代PCIe(非英伟达体系的主流方案)的可能。行业动态方面,2024年Intel发布的Gaudi-3加速卡集成了以太网网络,中国信通院发起的ETH-X(以太网)超节点计划亦开始探索以太网在scale-up网络中的应用,我们认为以太网已在scale-up网络中开启渗透。
Scale-out网络中,以太网仍有望凭借性价比获取市场份额。技术上,InfiniBand受益于协议自身的技术优势,能够在数据传输、故障修复以及用户对多租户方案的要求等方面满足智能计算要求,在TOP100中InfiniBand的占比显著高于以太网。但以太网也能够应对智能计算,且RoCE(以太网+RDMA)的成本更低、使用更普遍,智能计算厂商对其认知更充分,下游厂商仍可能倾向于使用以太网进行智能计算,TOP500中以太网的占比与InfiniBand日趋接近。展望长期,我们认为以太网将持续性能迭代,有望凭借经济型与普遍性胜出。
我们建议关注推理分布式部署下,以太网同时在scale-up与scale-out网络中渗透率提升所带来的投资机遇。
图表15:InfiniBand 与以太网在 TOP100 中占比

资料来源:TOP500官网,中金公司研究部
图表16:InfiniBand 与以太网在 TOP500 中占比
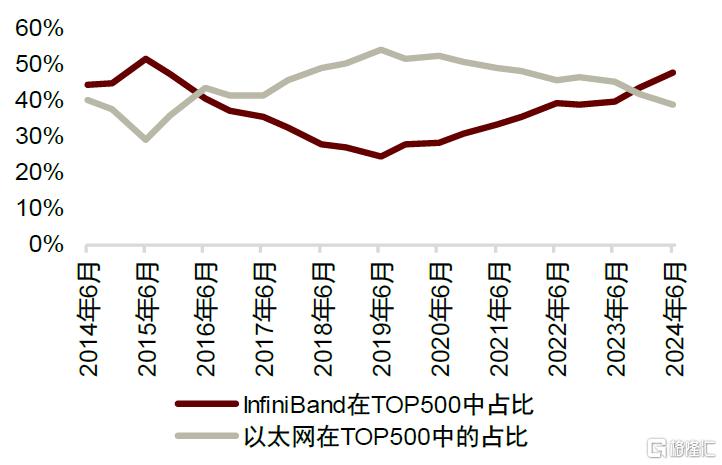 资料来源:TOP500官网,中金公司研究部
资料来源:TOP500官网,中金公司研究部
推理硬件市场增长:大模型平权带来广泛部署需求,接入高日活APP可带来数十万GPU需求
在AI进化论第一篇报告中,我们深度分析了训练成本降低实际会带来更广泛商业需求的逻辑,在推理端该逻辑依然适用。我们认为DeepSeek推理降本推动了推理需求的增长,短期内大量用户端部署的需求增长会对推理硬件市场增长构成直接拉动,下游应用生态的想象空间也被进一步打开。举例来看,近期阿里巴巴管理层也在最新业绩会中表示看到了推理需求的快速增加,并开始追加云资本开支投资。在大模型平权的趋势下,硬件投资和应用落地的闭环初见雏形。
图表17:“大模型平权”下的推理硬件需求逻辑

资料来源:DeepSeek V3技术报告,中金公司研究部
2月中旬,微信[5]开启灰度测试接入DeepSeek事件引发了市场的广泛关注。由于在EP=320高度并行状态下模型对显存占用空间较小(仅671GB/320=2GB)左右,且激活值在计算过程中被层层丢弃,我们将显存近似视为全部分配给KV Cache。在一定的基本假设框架下(见图17),我们测算出接入微信这类日活用户数达10亿级别APP所需要的NVIDIA Hopper GPU增量为40万左右,是较大体量的需求拉动。
图表18:典型DeepSeek模型在10亿日活数APP上部署对GPU的需求量及单token成本测算
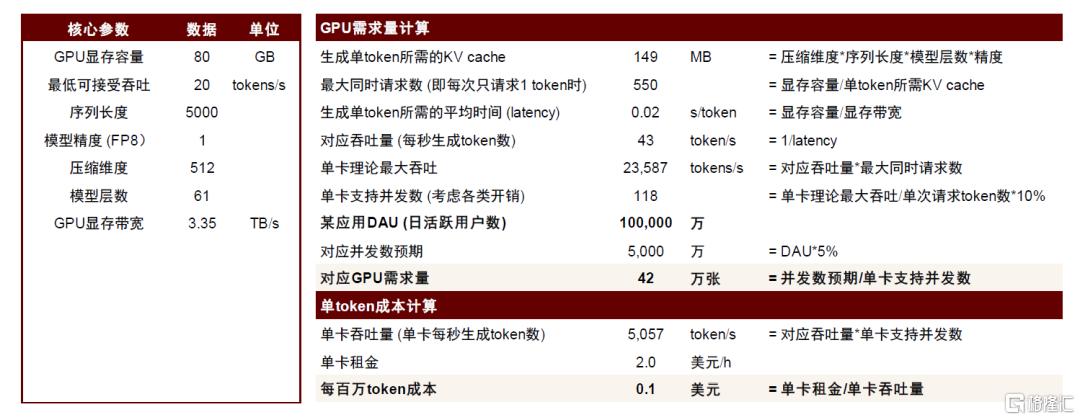
注:此表中GPU需求量为NVIDIA Hopper系列GPU等效需求;单卡支持并发数计算中乘以10%是考虑到有其他开销,实际并发数在理论并发数上有所折扣; 资料来源:DeepSeek-V3技术报告,中金公司研究部
国产算力的机会:从芯片到整机,全产业链加速适配DeepSeek
国产算力产业链全方位适配DeepSeek。1)芯片端,国产主流GPU厂商均已宣布适配DeepSeek,并结合AI infra厂商的算法优化,提供性能较优的推理体验。例如2月1日硅基流动[6]宣布与昇腾云合作推出DeepSeek R1/V3推理服务,据官方称在自研推理加速引擎赋能下可实现持平全球高端GPU部署模型的推理效果。2)整机端,多款一体机产品密集推出,满足下游对数据安全、数据隐私的需要。例如联想[7]基于沐曦N260,其Qwen2.5-14B的推理性能达英伟达L20的110-130%,支持DeepSeek各参数蒸馏模型的本地部署。3)IDC端,华为云、天翼云、腾讯云、阿里云、火山引擎等龙头云计算厂商均已上线DeepSeek,供下游个人及政企单位调用,例如腾讯在元宝、微信中接入DeepSeek。
根据芯东西统计,2025年2月1日-14日短短两周时间内,即有24家国产AI芯片企业、6家国产GPU企业、6家国产操作系统企业、86家国产服务器或一体机厂商以及82家中国云计算厂商及AI基础设施厂商,去重合计超过160家国产算力产业链企业宣布完成DeepSeek适配。我们认为,国产企业全方位适配DeepSeek有望加速AI应用侧的落地,反过来亦有望驱动AI本土产业链性能的升级共荣。
图表19:国产算力硬件产业链已全面适配DeepSeek大模型(不完全统计)
资料来源:公司公告,芯东西,中金公司研究部
图表20:配套国产芯片的服务器整机针对DeepSeek不同版本模型适配情况

资料来源:昇腾开发者官网,昆仑芯官网,中金公司研究部
风险
► 生成式AI模型创新不及预期。本次DeepSeek模型获得业内广泛关注的核心原因之一在于大量细节上的算法创新以及硬件工程创新。如果生成式AI模型技术创新停滞,将直接影响技术迭代与产业升级进程。
► AI算力硬件技术迭代不及预期。GPU的算力水平以及网络通信的传输速率均有可能成为AI大模型训练与推理的瓶颈,如果GPU算力及网络通信的瓶颈持续扩大,或会拖慢生成式AI进化迭代的速度。
► AI应用落地进展不及预期。AI大模型训练成本与推理成本较高,当前各互联网大厂纷纷加大资本开支以支撑对AI大模型的研究。但是如果迟迟没有现象级AI应用出现,当前的AI支出则无法变现,影响互联网大厂进一步投入的意愿。
本文摘自:2025年2月27日已经发布的《AI进化论(2):模型+工程创新持续唤醒算力,DeepSeek撬动推理需求蓝海》
成乔升 分析员 SAC 执证编号:S0080521060004
彭虎 分析员 SAC 执证编号:S0080521020001 SFC CE Ref:BRE806
贾顺鹤 分析员 SAC 执证编号:S0080522060002
陈昊 分析员 SAC 执证编号:S0080520120009 SFC CE Ref:BQS925
李诗雯 分析员 SAC 执证编号:S0080521070008 SFC CE Ref:BRG963
孔杨 分析员 SAC 执证编号:S0080524100002
主题测试文章,只做测试使用。发布者:北方经济网,转转请注明出处:https://www.hujinzicha.net/6674.html