
在AI进化论系列的前序报告中,我们深度分析了DeepSeek(下称DS)的开源与技术创新,并探讨训练及推理硬件的需求变化。得益于模型工程优化的创新,DeepSeek-R1表现出领先的成本优势和综合性能,其开源策略也降低了AI前沿技术的获取门槛,推升了下游客户对于AI大模型的本地部署需求,我们预期以一体机为代表的私有化算力硬件景气度有望向上。
摘要
C端场景:DeepSeek-R1蒸馏技术实现轻量化模型突破。R1蒸馏技术通过知识蒸馏,将复杂的“教师模型”(671B参数)的决策逻辑和特征表征能力迁移至轻量化的“学生模型”,生成了6个不同版本的蒸馏模型。这些蒸馏模型在保持大模型性能的同时,减少了对显存、内存和存储的需求,适合在资源受限的终端设备上运行。我们认为,PC是承载本地模型的重要终端,更高性能端侧模型的部署,有望成为AI PC产业升级的有力推手。
B端场景:DS一体机提供私有化部署的全栈解决方案。DS一体机是一种专为大模型应用和部署设计的集成计算设备,可基于NV或国产硬件实现,其中国产算力芯片由于契合主流下游需求,或成为主要算力支撑。
我们认为,当前DS一体机的软硬件协同仍面临一些挑战,1)主流国产AI芯片缺少对FP8精度的支持,如果采用FP16或BF16精度,硬件效率将下降;2)为了在单台8卡服务器上实现全参数DeepSeek-R1模型的部署,一体机厂商需要进行定点量化,需在算力效率和模型效果间寻求平衡。但得益于DS模型优势,以及一体机本地私有化、快速部署等优势,DS一体机国内市场空间有望快速提升。DS一体机在满足企业数据安全和合规要求方面具有优势,对于政府、金融等数据安全要求较高的行业适配度高,我们预估乐观情形下25年DS一体机市场规模有望达到540亿元。
风险
生成式AI模型创新/模型本地化部署需求/AI算力硬件技术迭代不及预期。
DeepSeek开源大模型推动私有化部署新趋势
中国企业DeepSeek(以下简称DS)全面开源的创新成果引发了市场对生成式AI技术发展与算力硬件需求的热烈讨论,其V3版本模型以仅1/10训练成本消耗便获得了与海外领先模型GPT-4o/Llama3.3对标的能力,并通过对V3同一基础模型的后训练获得R1模型,R1在后训练阶段大规模使用了强化学习技术,在仅有少量标注数据的情况下,提升了模型推理能力,在数据、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。此外,DS于2025年2月24日正式启动“开源周”,连续5天每天开源一个项目,丰富AGI领域的开源生态。
我们认为,高质量的开源模型有望推动AI大模型的能力边界探索,并加速AI应用落地,利好作为底层支撑的算力硬件需求。在此前的AI进化论系列报告中,我们探讨了训练硬件市场需求的变化,提出DS的创新是在命题作文下(中美贸易摩擦背景下AI硬件采购受限)的较优解,并未提出任何反“Scaling Law”的趋势,杰文斯悖论(Jevons Paradox)为DS带来的“大模型平权”创新行为影响指明了方向——全行业算力资源使用效率的提升,可能会创造更大的需求。在应用推理方面,我们看到DS在C端表现亮眼,根据Data.ai数据,DS APP自2025年1月11日发布以来,下载量呈指数级增长,1月20日至26日单周下载量达170万次,次周(1月27日至2月2日)达到1576万次,环比增长超800%,截至2025年2月24日,累计下载量已突破4000万次;在B端,DS的开源属性与模块化设计加速了其在垂直领域的渗透,包括政务、医疗、汽车、工业、金融等领域,根据爱分析[1]的统计数据,截至2025年2月21日,已有45%的央企完成了DS模型的部署。
图表1:DeepSeek APP下载量
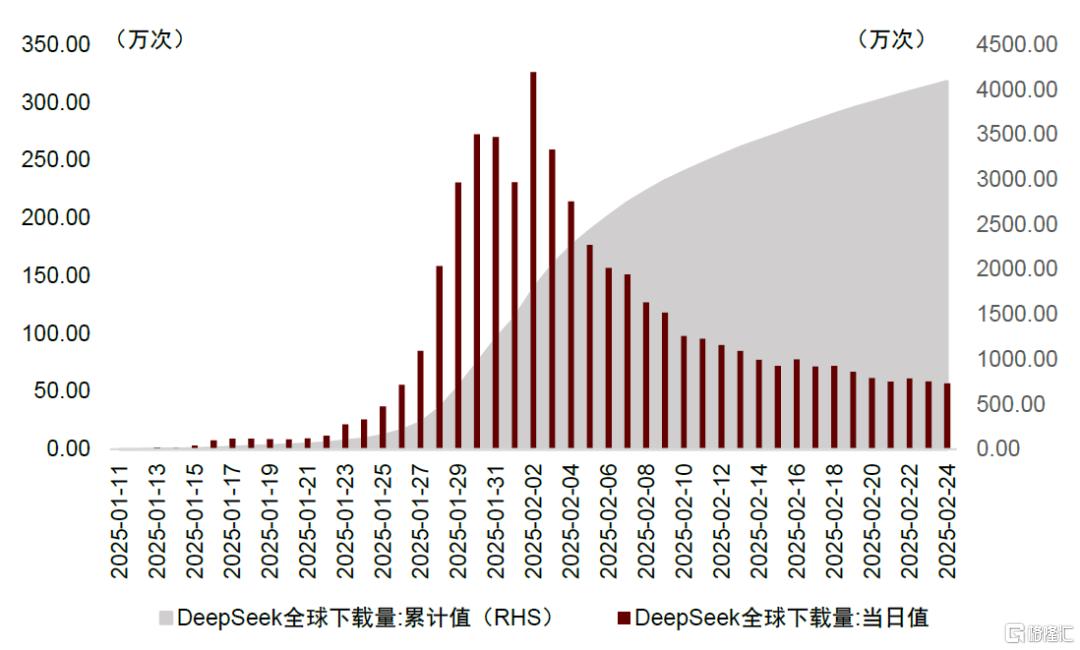

资料来源:Data.ai,中金公司研究部
大模型云端部署带动的云端算力需求提升,头部云厂商进入资本开支上行周期。大模型的云端部署以弹性算力和快速迭代见长,我们认为,R1模型作为高质量、低成本的模型代表,开发者通过云厂商调用API、部署模型并开发应用,有望推动云资源消耗量提升。根据阿里巴巴财报,AI推动阿里云收入增速持续提升,4Q24季度收入重回13%的同比双位数增长,AI相关产品收入连续六个季度实现三位数同比增长,单季度资本开支44.1亿美元,环比增长81%;业绩电话会上[2]集团CEO表示,未来三年云和AI基础设施投入预计超过过去10年总和,AI capex指引积极。
我们认为,DS部署不止于云端,本地化私有部署同样具备广阔的应用场景,私有化部署方式使得企业及个人能够完全掌控自身的数据环境,有力保障数据安全,降低数据泄露和遭受外部干扰的风险。
► C端呼唤云端协同范式:面向消费级AIPC等场景,”云端协同”成为优化体验与隐私保护的必然选择。通过将非敏感任务卸载至云端,可突破终端算力限制,支撑复杂模型推理;同时端侧部署轻量化模型处理隐私数据,既满足GDPR等法规要求,又减少网络依赖带来的延迟抖动及可能的体验中断。
► B端部分行业刚性需求驱动本地化部署:部分企业级市场对私有化部署呈现强依赖性,1)尤其是金融、医疗等行业公司,处理较多高度敏感的数据,本地化部署能够防止数据离开企业内部网络,降低数据被外部恶意行为者窃取或滥用的风险;2)定制化需求旺盛,需针对行业知识库进行微调训练,从而推动DS大模型形成容器化交付、私有化调优的完整解决方案体系,满足企业对模型所有权与控制权的双重诉求。
我们认为,DeepSeek R1具有技术开源和成本控制的核心特点,降低了企业及个人部署高水平AI大模型的门槛,有望推动包括DeepSeek一体机在内的本地私有化部署需求快速提升。
► 模型性能领先:DeepSeek R1在性能上对标国际前沿模型,在数据、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。
► 开源策略:在闭源模式下,企业依赖大模型厂商的服务订阅,成本与技术的不透明度高。对比之下,DeepSeek采用MIT开源协议,允许企业免费商用和二次开发,同时,在最新“开源周”,DeepSeek陆续开源了FlashMLA、DeepEP、DeepGEMM、并行优化策略等项目,涉及大模型推理框架、MoE模型、FP8计算性能等方面提升,降低了前沿AI技术的获取门槛。
► 硬件成本:在本系列的前序报告中,我们对DS团队最新开源成果中的创新进行深入分析,DS团队通过MLA(多头潜在注意力机制)、NSA(原生稀疏注意力机制)、Prefill/Decode分离、高度EP等技术创新,实现推理成本下降;同时,通过知识蒸馏等技术,实现参数量分别为1.5B、7B、8B、14B、32B和70B的蒸馏版模型,在保持大模型性能的同时,减少了对显存、内存和存储的需求,进一步降低本地私有化部署的硬件成本。
► 硬件适配优化:DeepSeek早期的模型训练基于NV硬件实现,例如DS团队开源了MLA相关内核(Kernel),解密MLA结构在NV硬件上的具体实现。但我们看到,国产主流GPU厂商已宣布适配DeepSeek,为基于国产卡的DeepSeek一体机的快速落地奠定了基础,而DS团队基于NV硬件的优化方式开源也为开发者优化适配其他硬件提供了思路。
综上所述,DeepSeek大模型的私有化部署需求迫切,本篇研究我们将聚焦DeepSeek本地私有化部署的硬件配置及技术难点、一体机的需求空间及产业链。
蒸馏模型利好C端部署,一体机方案收获B端青睐
C端:DeepSeek-R1+蒸馏技术,轻量化模型推动AI端侧部署
DeepSeek-R1蒸馏:“小模型”蕴含“大智慧”
知识蒸馏(Knowledge Distillation)的本质是知识迁移和压缩,其核心在于将复杂“教师模型”的决策逻辑与特征表征能力迁移至轻量“学生模型”。根据DeepSeek-R1技术论文[3],使用671B参数量的DeepSeek-R1(教师模型)生成80万条高质量训练数据,涵盖数学推理、编程、科学问答等场景任务,并通过规则过滤混合预研、冗余段落和代码块,最终数据样本中包括最终答案和多专家协作的决策逻辑;通过知识蒸馏技术,将671B参数大模型的复杂推理模式(如长链思考、自我验证等)迁移至轻量模型(学生模型),从而形成参数量为1.5B、7B、8B、14B、32B、70B的6个不同版本蒸馏模型。
图表2:“教师模型”通过知识蒸馏后得到“学生模型”
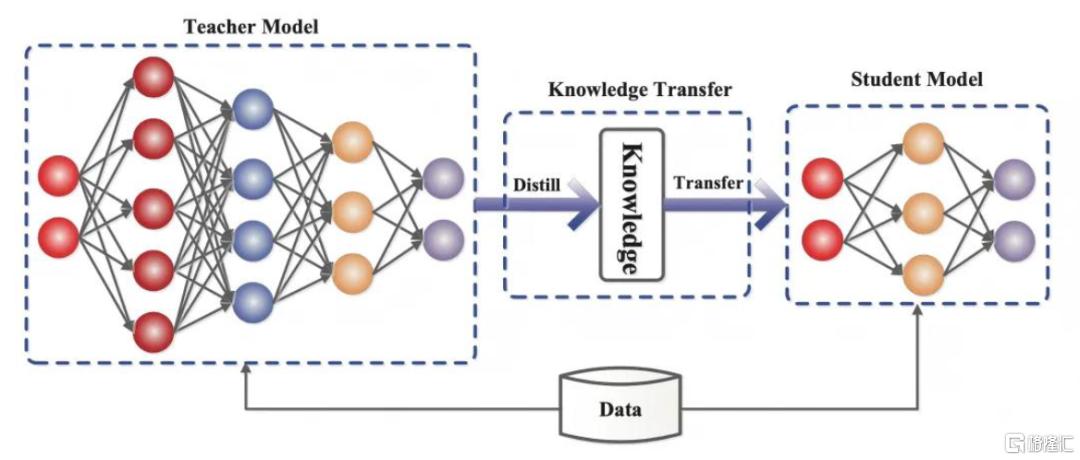
资料来源:Gou, J., Yu, B., Maybank, S.J., & Tao, D. (2020). Knowledge Distillation: A Survey. International Journal of Computer Vision,中金公司研究部
DeepSeek-R1蒸馏版模型的推理性能超越同规模传统模型。DeepSeek蒸馏技术融合了数据蒸馏与模型蒸馏,采用监督微调(SFT)方式,利用DeepSeek-R1生成的80万个数据样本对基础模型(如Qwen和Llama系列)进行微调,并且在架构优化中增加层次化特征提取、多任务适应性、参数共享与压缩等设计,实现了高效的知识迁移。得益于模型结构优化和蒸馏技术的应用,蒸馏版本模型在多个推理基准测试中表现优异,根据DeepSeek-R1技术论文,DeepSeek-R1-Distill-Qwen-7B在AIME 2024基准测试中实现了55.5%的Pass@1(模型首次生成答案即正确的概率),超越了QwQ-32B-Preview,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上则实现了72.6%的Pass@1,在MATH-500上实现了94.3%的Pass@1,超过了OpenAI-o1-mini。
论文还进一步对比了蒸馏模型和基于Qwen-32B-Base模型、使用数学、代码和STEM领域数据进行了超过1万步大规模强化学习(RL)训练而来的小模型,结果显示,在所有推理基准测试中,蒸馏模型DeepSeek-R1-Distill-Qwen-32B均优于后者(DeepSeek-R1-Zero-Qwen-32B),且耗费更少的计算资源,兼具经济性与有效性。我们判断主要得益于蒸馏的知识迁移优势、更高效的学习过程、以及继承了教师模型一部分泛化能力。
图表3:DeepSeek-R1蒸馏模型与其他模型推理性能对比
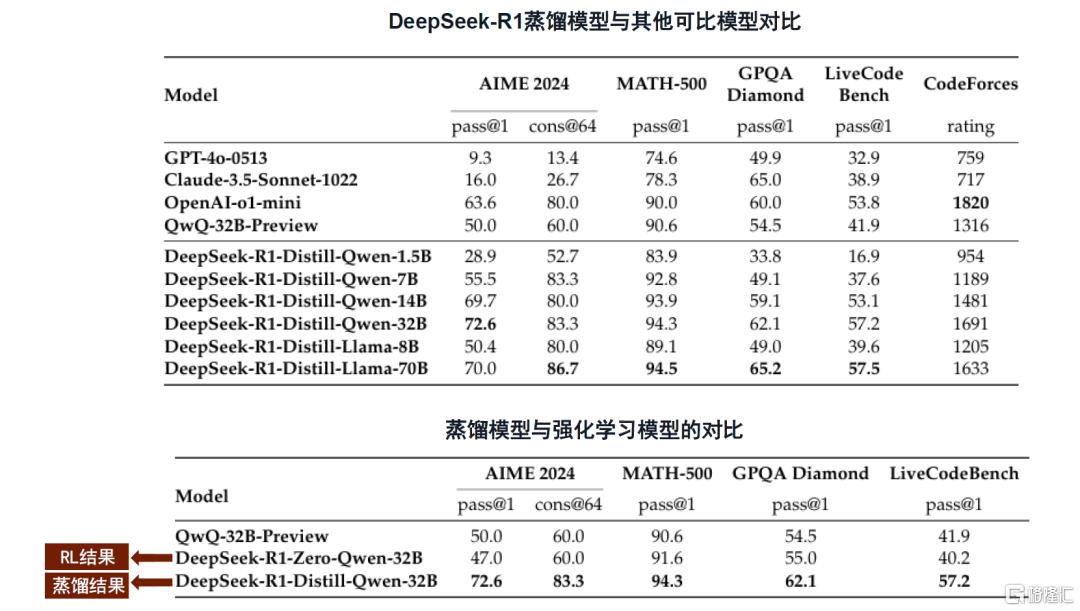
注:Pass@1指模型首次生成答案即正确的概率,主要评估模型的及时响应能力;Cons@64是通过64次独立生成答案后取多数投票结果作为最终答案的评估指标,主要评估多次采用后的稳定性和一致性。
资料来源:DeepSeek-R1技术报告,中金公司研究部
DeepSeek-R1蒸馏模型本地部署的硬件要求?
传统大模型在推理时需要大量计算资源、以及足够大的内存和存储空间,如满血版671B参数量的DeepSeek-R1在采用FP8训练(精度系数为1)时,显存需求约850GB,若采用INT4量化,只考虑加载模型参数仍需占用313GB的显存,对内存和硬盘空间的要求也较高,超出PC、手机等终端设备的硬件承载阈值。蒸馏模型在尽量保持大模型性能的基础上,减少了对显存、内存和存储的需求,更加适合搭载于资源受限的终端设备,适用于C端场景。
DeepSeek-R1蒸馏模型的本地部署需要根据模型大小和计算需求,选择合适的终端硬件配置。蒸馏后的DeepSeek-R1模型可以通过Ollama和AnythingLLM实现PC本地部署。根据联想官网信息[4]以及ollama[5],我们梳理了运行不同版本参数蒸馏模型所需的硬件配置:
若只运行1.5B的超轻量模型,具备实时基础问答、文本情感分析等功能,集成显卡的配置基本足以支持;若需要执行中等复杂度任务如文本摘要、翻译、图像描述生成等,需部署7B或者8B端侧模型,INT4量化假设下的最低显存要求需达到4-5GB,普通的消费级硬件(如RTX 3060/3070/4060等)可支持运行,推荐内存配置为16GB+,硬盘容量大于10GB;若要部署14B中型模型,用于跨模态理解、复杂代码生成、本地知识库检索等任务,需升级硬件配置,采用RTX 4090/A5000或更高显存的显卡、以及32GB+的内存和15GB+的硬盘存储;而对于32B或70B较大参数量模型的本地部署,以实现多模态任务处理、科研数据分析、复杂语义理解等任务,对PC硬件提出了更高要求,通常需要配置专业级GPU(NVIDIA A100/H100,或采用多卡并行,INT4量化假设下最低显存要求接近40GB,推荐显存大小为80GB,并提出更大的内存和存储、更高的散热和电磁屏蔽等要求。
PC是承载本地模型的重要终端,更高规格、性能端侧模型的部署正在成为AI PC升级的有力推手。2月25日,联想[6]推出全球首批端侧部署DeepSeek的AI PC产品——YOGA AI PC元启系列,在消费级设备上实现70亿参数端侧模型的流畅运行,用户文档的总结、翻译、撰写等操作无需调用云端大模型即可完成,提升了推理效率,充分保障了数据隐私与离线可用性,还可以根据用户个人需求进行定制化训练。
我们认为,AI PC的换机动力仍有提升空间,此前主要受制于端侧模型能力有限、国外厂商API调用限制、以及价格高昂;DeepSeek-R1基于知识蒸馏的轻量化模型在本地推理性能上表现优异,以更小参数量实现接近原模型的精度,降低了端侧AI任务的门槛。我们认为,PC作为生产力工具,其用户追求性能体验,随着应用场景逐步扩展到多模态任务处理、复杂推理等领域,用户对更优性能、更高规格本地模型部署的需求攀升,传统PC的算力与内存配置逐渐成为瓶颈,硬件升级趋势明确,端侧模型进化与硬件迭代形成飞轮效应、有望加速AI PC渗透。
图表4:不同参数量裁剪版DeepSeek-R1模型本地部署的硬件要求
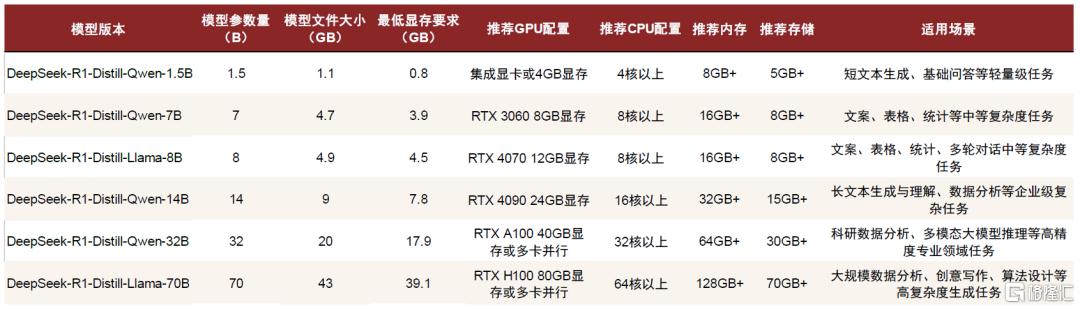
注:1)模型文件大小来源于Ollama官网模型下载文件的大小;2)最低显存要求的计算方式:假设均采用INT4(4比特)量化,每个参数占用0.5字节,且考虑到实际部署时需预留额外显存用于存放中间计算和框架开销,这部分额外开销一般占模型本身大小的20-50%,我们采用20%保守计算,显存需求(GB)≈参数规模(B)*每个参数的字节数/ (1.024)^3)*(1+20%)
资料来源:Ollama官网,CSDN,联想集团官网,中金公司研究部
B端:AI私有化部署新趋势,DeepSeek一体机的全栈式解决方案
DeepSeek一体机重构本地私有化AI部署模式
DeepSeek-R1全参数模型拥有671B参数,相较于32B参数的蒸馏版,展现出更强的数学、代码及逻辑推理能力,为B端用户所需要;但也对系统显存容量、显存带宽、互连带宽、延迟等提出了更高的要求。根据安擎[7],MoE模型运行所需的显存可以由公式——模型参数量×精度系数+激活参数量×精度系数+10%~20%其他消耗——计算得到,对于DeepSeek R1而言,模型参数为671B,单次激活专家参数量为37B,模型主要采用FP8训练(精度系数为1),则所需的显存约为850GB。
图表5:DeepSeek-R1模型性能表现
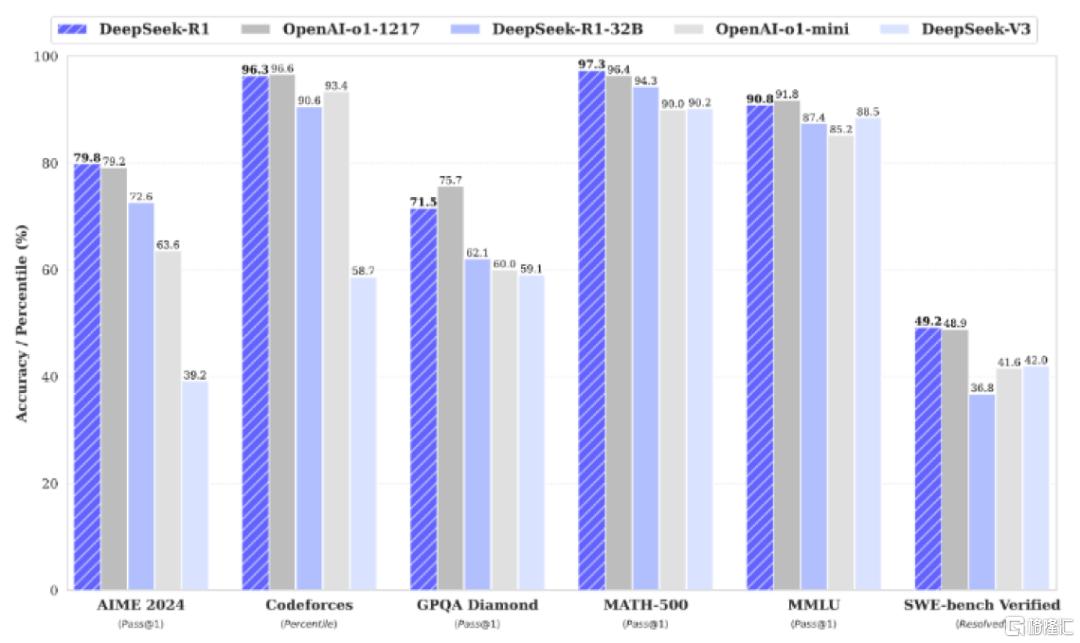
资料来源:DeepSeek,中金公司研究部
一体机是一种专为大模型应用和部署而设计的集成计算设备,形成“开箱即用”的智能算力解决方案。一般而言,大模型的私有化部署工作量大且部署流程较长,前期在硬件端需要对AI服务器、存储设备、网络设备等ICT硬件进行选购及配置,在软件端需要将大模型与硬件环境适配,处理兼容性等问题,在部署阶段需要经历系统调试等流程,后期还需要专业的运维团队进行维护管理。相比而言,大模型一体机作为“软硬协同、开箱即用”的智能化基础设施,高效耦合计算、存储、网络等硬件设备、大模型微调部署软件平台和预置大模型,能够缩短部署周期、深度结合场景、降低落地门槛,重构本地私有化AI部署模式。
► 深度优化的高性能硬件:大模型一体机通过适配专用AI芯片,针对大模型算法进行深度优化,可以充分释放AI芯片性能;通过配置大容量内存和高速存储,支持大模型的加载和运行,提高数据读写速度。目前,基于昇腾、百度昆仑芯等国产芯片打造的DeepSeek一体机,都对推理性能进行了优化。中国电信[8]推出的息壤智算一体机,基于华为昇腾芯片,借助自研推理加速引擎,充分发挥DeepSeek性能;浪潮元脑R1推理服务器[9]支持昆仑芯AI芯片并进行深度优化,解决DeepSeek-R1全参数模型部署中的资源瓶颈,从而提升推理效率。
► 内置多种基座大模型:目前的大模型一体机可以提供包括DeepSeek系列、LLaMA系列、Baichuan系列、Qwen系列等在内的多种主流开源大模型,企业用户可以根据特定应用场景需求,对预置模型进行微调及增量训练,降低AI大模型的落地门槛。紫鸾大模型一体机[10]预装DeepSeek R1、Baichuan2、Qwen2、GLM-4、LLAMA等主流大模型及完整运行环境,通过图形化界面,用户可在数分钟内启动模型并投入使用。
► 全栈工具链:大模型一体机通过集成AI全流程开发工具,实现从数据处理、模型训练到推理部署的全栈式开发,提高模型训练效率。同时,通过外挂用户专属知识库,结合检索增强技术,实现专业领域的知识问答,为企业提供定制化、便捷化、场景化的AI服务;通过可视化管理工具,实现硬件组网、资源监控、故障定位清晰可见,降低运维门槛。
图表6:大模型一体机参考架构
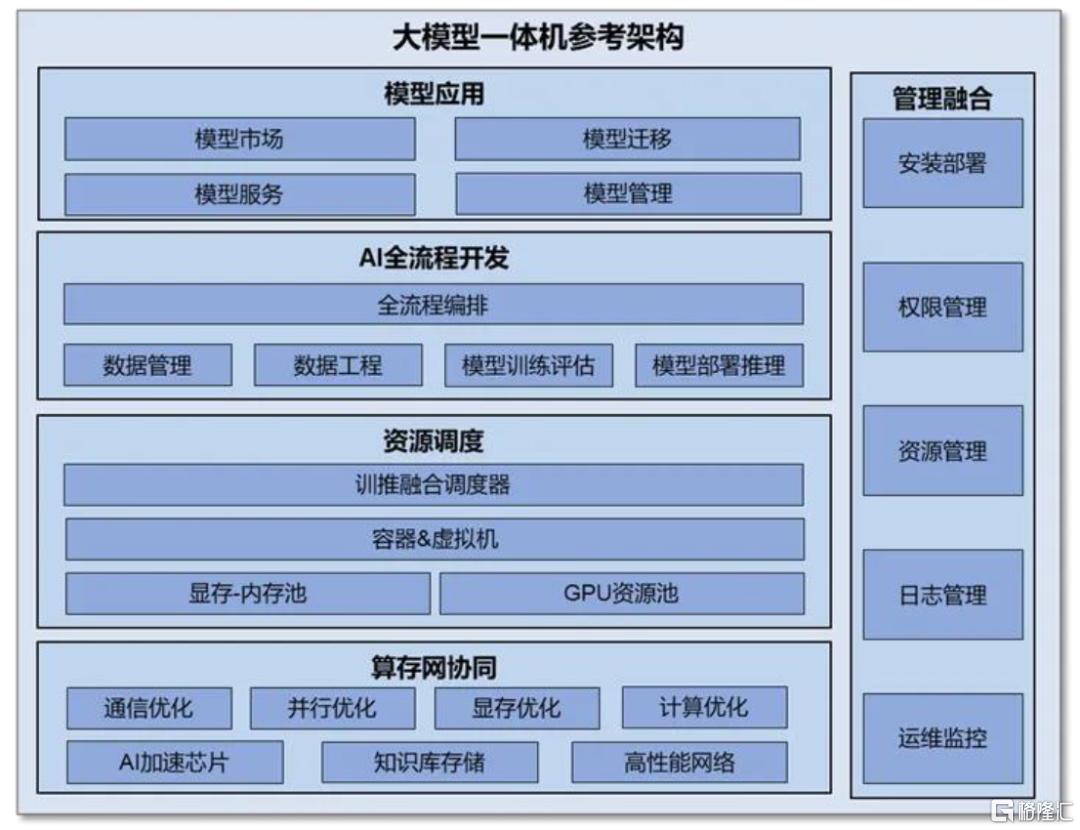
资料来源:中国信通院,中金公司研究部
DeepSeek一体机软硬件协同难点
当下主流国产AI训练芯片缺少对FP8精度的支持是运行DS模型的一大问题,采用16位精度单元计算会大幅降低效率。DeepSeek采用的是FP8混合精度,但当前主流的国产AI训练芯片缺少对FP8精度的支持,如果采用BF16或者FP16来计算,理论上对精度影响较小,但是对计算和显存的硬件需求几乎增加一倍。采用上节相同计算方法,采用FP8精度部署671B的DS大模型,显存需求约为850GB;如果采用FP16或者BF16部署DS大模型,显存需求约在1.5T以上,以阿里云百炼专属版AI训推一体机[11]为例,单机部署全精度16/8/4bit下高并发满血版DeepSeek-R1/V3,部署16卡,显存达到1,536GB。
图表7:中国AI芯片显存大小及支持的数据精度

资料来源:摩尔线程官网及公众号,半导体产业纵横,京东,华为,中国算力大会,海光信息,昆仑芯,寒武纪,云轩Cloud Hin,Hot Chips,燧原科技,中金公司研究部
图表8:百炼专属版AI训推一体机

资料来源:阿里云政企公众号,中金公司研究部
DeepSeek R1模型全参数配置的显存要求较高,通过定点量化压缩显存占用。以FP8精度部署DS R1全参数模型所需的显存为850GB,同时,由于大部分国产AI芯片只支持INT8、FP16、FP32等格式,如果采用FP16精度,单机显存要求将进一步提升至1.5T显存以上,超出单台8卡AI服务器的显存范围。为了在单台8卡服务器上实现671B全参数DeepSeek R1模型,厂商需要进行定点量化,即通过降低模型中的参数精度(如从16位浮点数转换为8位)来减少模型的大小与计算复杂度,从而降低显存占用并提高吞吐效率,并保持可接受的精度损失范围。以INT 8量化——即将模型从浮点数转换为8位整数——为例,模型的权重和激活值会经过缩放、偏移等量化过程,以尽量多地保留原始浮点数的信息,在推理过程中,这些定点量化值会被反量化回浮点数进行计算,然后再量化回INT8进行下一步。
图表9:INT8量化示意图
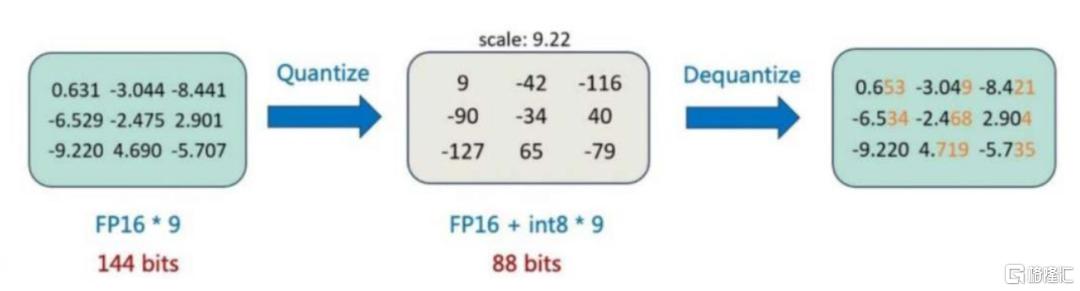
资料来源:53AI,中金公司研究部
DeepSeek一体机并非AI服务器硬件与大模型的简单叠加,可能会遇到无法部署或资源浪费的问题,一体机厂商需要围绕AI芯片与大模型进行深度适配,并在优化算力效率与保障模型效果之间寻求平衡点。
DeepSeek一体机迎合本地化部署需求,市场空间广阔
满足本地化及快速部署需求,DeepSeek一体机市场空间广阔
DeepSeek一体机私有化部署,满足企业数据安全及合规需求。《网络安全法》、《个人信息保护法》要求企业进行数据分类管理、备份加密、部分关键敏感信息须在境内存储;此外,在一些特定行业,如金融、医疗、能源等,有专门的数据安全和隐私保护行业标准和规范,政府部门也存在敏感信息的本地化需求。DeepSeek一体机部署在企业内部机房等环境,企业对于硬件设备拥有完全的控制权,数据仅在公司内部网络流转,与外部网络实现物理隔离或严格的逻辑隔离,避免了数据在公共网络环境中传输和存储可能面临的被拦截、窃取等风险,提升了数据安全性;此外,DeepSeek一体机可以根据行业特点和要求进行定制化配置和功能开发,满足行业标准中对于数据安全、审计、备份恢复等方面的规定,例如金融行业对交易数据的完整性和保密性要求,医疗行业对患者隐私数据的保护要求等。
图表10:“云+大模型”环境下数据安全挑战
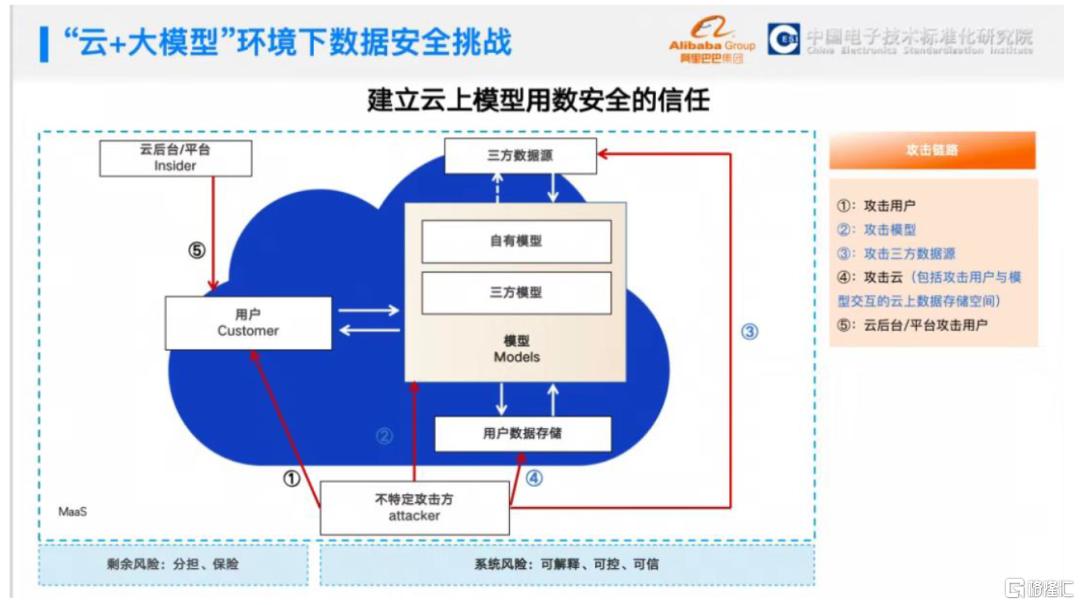
资料来源:阿里巴巴人工智能治理研究中心公众号,中金公司研究部
DeepSeek一体机降低AI大模型的部署门槛。政企客户行业分布广泛,部分企业客户开发经验有限,通常需要全面的售前售后服务支持。目前,DeepSeek一体机厂商提供两项解决方案:“开箱即用”的部署模式、通过集成工具降低AI开发和应用门槛。
► “开箱即用”部署模式:实现DeepSeek一体机小时级一站式交付、即插即用,配备一个大模型开发平台,综合覆盖多元多模数据处理、RAG(检索-生成)以及数据安全等关键环节。厂商将结合客户的具体需求和数据,对大模型进行开发优化,并配备ISV在现场进行数据治理、模型微调等复杂流程的整合和部署,以加速企业AI应用的落地。对比传统的数据准备、清洗、治理和跨平台的训练、微调生态流程,DeepSeek一体机将帮助企业节约大量迭代时间。
► 自主微调模式:针对企业自主微调大模型的需求,DeepSeek一体机集成主流有效的微调方法,内置多种大模型计算框架和基础模型,微调采用低代码可视化界面,内置了如Lora、SFT等多种微调框架和优化参数,有效降低复杂性和技术门槛,企业用户能根据具体需求和数据特性选择合适的技术、快速开发和部署模型应用。
减弱B端用户对云的依赖。公有云可以为企业提供短期内大规模的计算资源,同时支持与云服务提供商自有的AI技术进行协作,从而满足企业推理需求,但同时也存在稳定性、总成本的风险。稳定性方面,公有云的平稳运行取决于云环境及通信网络,宕机事件或网络不稳定都会导致推理业务中断;总成本方面,对于长期模型推理的使用者,云服务的费用随时间不断攀升,且在后期升级时,成本的不可预见性可能会加重企业的资金负担。DeepSeek一体机采用单次买断制,有利于企业用户控制资本开支及AI部署成本。
DeepSeek一体机市场空间测算
AI大模型能够有效提升政府工作效率,深圳市福田区[12]已上线11大类70名“数智员工”,满足240个政务场景的需求,其中,个性化定制生成时间从5天压缩至分钟级,公文格式修正准确率超95%,审核时间缩短90%,错误率控制在5%以内。此外,医疗、金融等行业及央国企由于涉及敏感信息,对于数据安全的要求较高。
我们认为,DeepSeek大模型一体机作为开箱即用的私有化部署方案,在实现快速部署AI大模型的同时,能够满足对于公民信息、关键业务数据等数据安全保障的需求,有望受益于政府及企业的AI转型趋势。
DeepSeek一体机有望达到500亿元级别市场空间。根据IDC,2025年中国服务器市场出货量有望达到488万台,政府、金融、公共事业、医疗等6大政企行业由于涉及隐私数据,存在本地私有化部署需求,2021年上述行业占中国服务器市场需求约28%。我们预计,乐观情景下2025年上述行业约5%的需求转向DeepSeek一体机,则需求达到7万台,市场规模有望达到540亿元。
图表11:2025年国内DeepSeek一体机市场空间测算
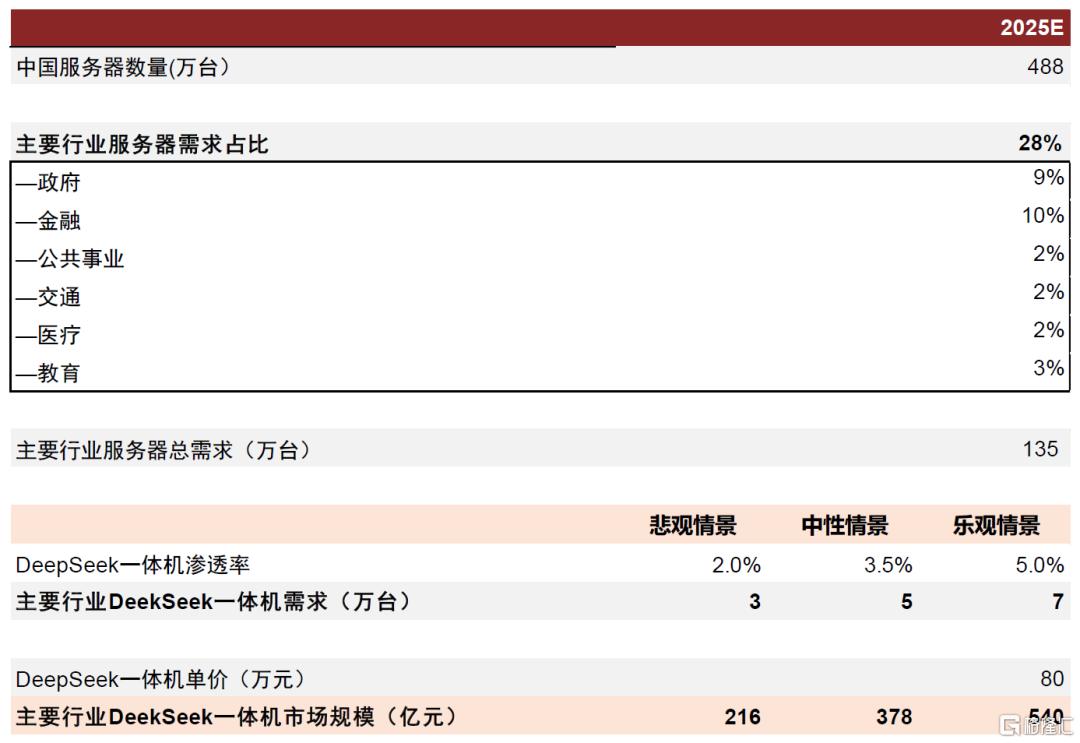
注:DeepSeek一体机单价因配置不同而存有较大差异,测算中采用中位数水平单价 资料来源:IDC,中金公司研究部
国产算力产业链全方位适配DeepSeek,服务器及云厂商拥抱一体机趋势
国产算力产业链全方位适配DeepSeek,一体机方案中国国产AI芯片成为重要底座。一方面,国产主流GPU厂商已宣布适配DeepSeek,并结合AI infra厂商算法优化,提供性能较优的推理体验,例如2月1日硅基流动[13]宣布与昇腾云合作推出DeepSeek R1/V3推理服务,据官方称在自研推理加速引擎赋能下可实现持平全球高端GPU部署模型的推理效果。
此外,整机厂商及IDC云厂商也积极适配DeepSeek,根据芯东西统计,2025年2月1日-14日短短两周时间内,即有24家国产AI芯片企业、6家国产GPU企业、6家国产操作系统企业、86家国产服务器或一体机厂商以及82家中国云计算厂商及AI基础设施厂商,合计超过160家国产算力产业链企业宣布完成DeepSeek适配。另一方面,目前已有的DeepSeek一体机方案中,昇腾等国产GPU也成为重要的底层算力支撑。
我们认为,DeepSeek一体机有望加速AI应用落地,同时,有望推动AI本土产业链性能的升级共荣。
图表12::国产算力硬件产业链已全面适配DeepSeek大模型(不完全统计)
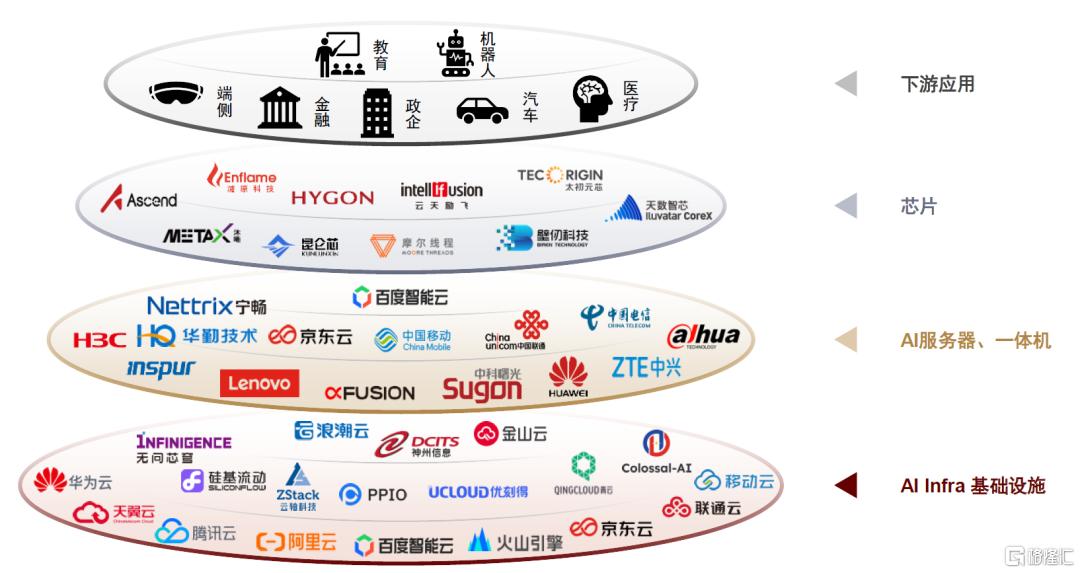
资料来源:公司公告,芯东西,中金公司研究部
算力硬件厂商、云厂商等均推出DeepSeek一体机,积极拥抱私有本地部署趋势。我们看好整机环节头部的一体机供应商。
图表13:DeepSeek一体机在位厂商布局一览
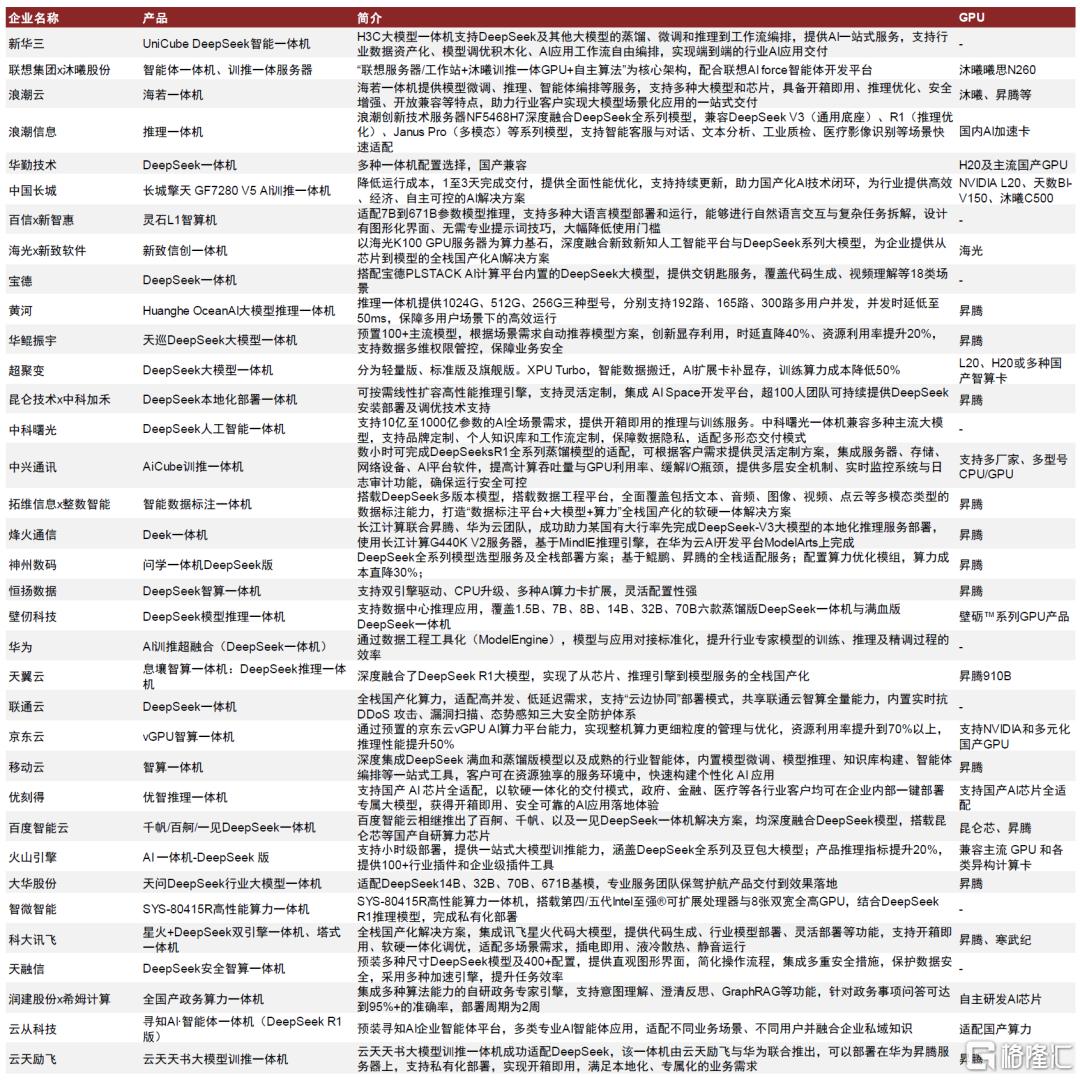
资料来源:新华三官网,c114,长城官网,新智惠想公众号,宝德服务器公众号,黄河科技集团公众号,华鲲振宇公众号,超聚变公众号,拓维信息公众号,中科加禾公众号,中科曙光公众号,中兴通讯官网,烽火通信公众号,恒扬数据公众号,壁仞科技公众号,天翼云官网,CWW,京东云微信公众号,移动云官网,优刻得官网,百度智能云官网,火山引擎公众号,IT之家,浪潮集团官网,浪潮计算机公众号,大华股份公众号,科大讯飞公众号,天融信官网,神州数码官网,华勤技术公众号,新致软件公众号,智微智能公众号,中金公司研究部
相关风险
生成式AI模型创新不及预期。本次DeepSeek模型获得业内广泛关注的核心原因之一在于大量细节上的算法创新以及硬件工程创新。如果生成式AI模型技术创新停滞,将直接影响技术迭代与产业升级进程。
模型本地化部署需求不及预期。B端及C端对于AI大模型本地化部署需求受到AI大模型技术迭代、硬件部署成本、IT采购预算等多方面的影响。如果上述因素出现扰动导致下游模型本地化部署需求不及预期,或对AI PC及一体机市场空间造成负面影响。
AI算力硬件技术迭代不及预期。GPU的算力水平、显存大小及生态建设均有可能成为DeepSeek本地部署的制约因素。随着市场对AI应用需求不断增长,对一体机的性能要求也会日益提高,一体机作为集成了多种硬件和软件功能的综合性设备,其性能在很大程度上依赖于GPU的算力支持。如果GPU算力瓶颈扩大,可能对一体机的需求产生不利影响。
本文摘自中金公司2025年3月5日已经发布的《AI 进化论(3):DeepSeek本地部署需求盛行,一体机硬件乘风而上》
李诗雯 分析员 SAC 执证编号:S0080521070008 SFC CE Ref:BRG963
朱镜榆 分析员 SAC 执证编号:S0080523070002
郑欣怡 分析员 SAC 执证编号:S0080524070006
成乔升 分析员 SAC 执证编号:S0080521060004
彭虎 分析员 SAC 执证编号:S0080521020001 SFC CE Ref:BRE806
陈昊 分析员 SAC 执证编号:S0080520120009 SFC CE Ref:BQS925
主题测试文章,只做测试使用。发布者:北方经济网,转转请注明出处:https://www.hujinzicha.net/7767.html